
Getting started in ML Flow: Local server and Experiment Tracking
Before you can run, you must walk. And before you can walk, you must crawl. This post serves as a crawl through of getting up and running with ML Flow so that you are equipped to start exploring some of its introductory features - notably, its powerful experiment tracking.
We had thought about breaking this out into a series, where we progressed through learning all the features of ML Flow, layering them together like a beautiful chocolate cake. But as we scoped it out, it was morphing slowly into something more akin to Rachel's trifle cake from season 6 episode 9 of Friends. MLFlow - Good. Experiment Tracking - Good. Tensorflow Integration - GOOD!
We were getting a little hung up on the endless possibilities for constructing a finite series that adequately covered the basics but also made meaningful ground on the more sophisticated features. So instead - we offer this humble opening tutorial to help the uninitiated become acquainted with the basics of the ML Flow platform.
Sign up to the newsletter for our ML Flow deep dives as we will be releasing future posts where we walk, run and fly through some of the more advanced features in a more targeted approach. Hopefully whatever we bake up will be worthy.
At the end of this crawl-through, you will be able to:
Run MLFlow locally, using the python package
Run a simple experiment where you will track the development of a logistic regression model
Tag the experiment metadata through the UI and Python API
Run nested experiment runs for compartmentalization
Add arbitrary artifacts to your experiment runs
Pre-Requisites
You can follow through this tutorial on your local machine, but depending on your OS, you may need to alter some of the commands. The commands a unix based system with bash installed.
You can also follow along utilizing Docker, to provide a more streamlined experience with less dependency headaches. To utilize the docker instructions ensure:
Docker CLI installed on your machine
Docker is active/running on your machine
Read More: MLFlow for Machine Learning Teams
Setting up your environment
Start by cloning the companion git repository for this tutorial to your machine. Select an appropriate location and in your terminal, navigate there. Then clone the github repository with:
git clone https://github.com/shannonalliance/mlflow-tutorial
Once you have cloned the repository, in your terminal navigate to the tutorial folder:
cd mlflow-tutorial
Starting the Docker Container
Note: If you are running this tutorial locally, you can skip forward to “Initializing the virtual environment”.
Pull the python:3.8 docker image:
docker pull python:3.8
Once the image is ready, we are going run the container in detached mode, mounting ./Chapter01/python and exposing port 8080.
Note: This is for experimentation purposes only, do not follow these instructions in a production environment.
docker run -d --name=mlflow_chapter_01 -p 8080:8080 -v ./Chapter01/python:/Chapter01 python:3.8 tail -f /dev/null
After we run this command, the terminal will print the container id. Take note of this, you will need it in a moment.
Starting an interactive session with the container
Open a new interactive terminal session with the container by running the following, replacing <container_id> with the value retrieved above.
docker exec -it <container_id> /bin/bash
Change directories in to the mounted Chapter01 directory, which contains the python files needed for this tutorial:
cd Chapter01
Initializing the virtual environment
Note: For users running this tutorial outside of docker, we need to make sure we change in to the correct directory for the next set of commands to work appropriately.
cd Chapter01/python # For users running this tutorial locally, only.
We are going to start a virtual environment which we will use to install our dependencies. Start by running the command below:
python -m venv .venv
Activate your virtual environment with:
source .venv/bin/activate
Make sure your version of pip is up-to-date by running
python -m pip install --upgrade pip
Install requirements which include mlflow:
python -m pip install -r requirements.txt
Verify installation and check the version installed by running:
mlflow --version
Expected Output as of this command:
>> mlflow, version 2.11.3
Add a value for the MLFLOW_TRACKING_URI special MLFlow environment variable. This specifies the server's URI where MLFlow will log experiment data.
For this example, we are using a local server, so we aren't worrying about remote tracking.
export MLFLOW_TRACKING_URI=http://127.0.0.1:8080
Confirm that the environment variable was correctly exported:
echo $MLFLOW_TRACKING_URI
Expected output:
>> http://127.0.0.1:8080
The below command will start the MLFlow server on port 8080 and makes sure any experiments and their artifacts will be stored in their relative directory.
mlflow server --backend-store-uri mlruns --default-artifact-root mlruns --host 0.0.0.0 --port 8080
Example Output:
>> [2024-04-03 11:26:30 -0700] [14860] [INFO] Starting gunicorn 21.2.0
>> [2024-04-03 11:26:30 -0700] [14860] [INFO] Listening at: http://0.0.0.0:8080 (14860)
>> [2024-04-03 11:26:30 -0700] [14860] [INFO] Using worker: sync
>> [2024-04-03 11:26:30 -0700] [14862] [INFO] Booting worker with pid: 14862
>> [2024-04-03 11:26:31 -0700] [14863] [INFO] Booting worker with pid: 14863
>> [2024-04-03 11:26:31 -0700] [14864] [INFO] Booting worker with pid: 14864
>> [2024-04-03 11:26:31 -0700] [14865] [INFO] Booting worker with pid: 14865
Navigate to the UI which should be located at the localhost on port 8080.

When you navigate to the ui, you will see a default experiment. This cannot be removed. If you try you will receive a pop-up error:
INTERNAL_ERROR: Cannot delete the default experiment '0'. This is an internally reserved experiment.
Keep this terminal window open and running the MLFlow server. Do not close or exit the terminal. We will continue to use this for the rest of the chapter. Open up a new terminal session to continue the rest of the instructions.
Read More: Mastering ML Ops: A Blueprint for Success
Running our first experiment
In this initial demonstration, we will run a basic experiment. It involves training a logistic regression model on the iris dataset.
Later on we will train a more interesting model, but for now our precious flower model will serve to demonstrate some of the basic functionality of MLFlow.
Entering the docker container and activating the virtual environment
Note: If you are running this tutorial locally, you can skip forward to “Running the experiment”.
First, lets start by opening a new terminal window and opening a new interactive terminal session with the docker container, replacing <container_id> with the value retrieved earlier.
docker exec -it <container_id> /bin/bash
Change directories in to the mounted Chapter01 directory, which contains the python files needed for this tutorial:
cd Chapter01
Activate the virtual environment. This will allow us to now run our experiments with the packages from earlier installed.
source .venv/bin/activate
Running the experiment
We will train our first model by running the command below.
python train_iris_01.py
You can inspect the python file to observe what it does, however it's a fairly simple model fitting process.
What we should pay attention to are the mlflow module methods in use:
mlflow.start_run: used to start the run contextmlflow.log_param: used to log parameters utilized in the model training (e.g. # of folds in k-fold cross-validation)mlflow.log_metric: used to log model metrics that will be visualized in the MLFlow UI (e.g. model accuracy)mlflow.sklearn.log_model: used to log the model in MLFlow. The sklearn model will include instructions when viewed in the UI on how to utilize the model.
Below is and abridged version of the python script which shows the utilization of the above methods:
...
...
with mlflow.start_run():
...
...
mlflow.log_param("max_iter", 200)
mlflow.log_metric("avg_val_accuracy", avg_accuracy)
...
...
# Log each fold's accuracy
for i, score in enumerate(cv_scores, start=1):
mlflow.log_metric(f"fold_{i}_accuracy", score)
...
...
mlflow.sklearn.log_model(model, "logistic_regression")
...
...
Exploring the mlflow metadata
Remember when we started the server, we instructed it to use a relative path for storing experiment data. Running python train_iris_01.py will create a mlflow directory within the mounted folder.
Locally, we will see this within the Chapter01/python directory.
Within the newly created mlflow directory, we will see it also created a directory with the id of the experiment.
Within this experiment directory, there will be a set of directories associated with each run of the experiment. Each time we execute the python script, it will add a new run here.
The hierarchy of the mlflow directory follows the following pattern
101
└── mlruns
├── experiment_id
│ └── run_id
│ ├── artifacts
│ ├── metrics
│ ├── params
│ ├── tags
│ └── meta.yaml
└── meta.yaml
The run data includes information including the artifacts we saved (in this case our logistic regression model), the metrics and params we logged as well as tags and the runs meta.yaml which stores the related metadata.
Exploring the experiment data in the UI
Let's view this information in the UI next. Navigating to the localhost on port 8080, check the box in left side panel for the Iris Model with Cross Validation

Click the model link for the run, which was given an arbitrary name (in the example below it is crawling-panda-403). This provides a high level summary of this run of your model.

Read More: Fully Managed MLOps Platforms vs Custom Solutions
Tagging our experiment run
We can add tags to our model. Align this with your teams workflow for releasing models. We are going to add a tag for model_type for demonstration purposes. Some guidance on tags are provided below:
Annotation: This is probably the most straightforward use of tags. You can add descriptive tags to help understand the run better. These could include things like "baseline model", "final model", "uses new feature set", etc.
Categorization: Tags can be used to group similar model runs together. For example, you may want to tag all runs belonging to a specific ML model type, such as "RandomForest", "LinearRegression", etc.
Filtering: During the analysis phase, tags can be used to filter runs. For example, you may want to see only the runs that used a specific feature set or a particular algorithm.
Version Control: You can tag model runs to keep track of different versions of your machine learning models. This could be especially useful in case you want to revert back to a previous version.
Linking to More Information: Sometimes, you may want to link a run to more extensive documentation or source code. In such cases, you can use tags to add URLs linking to the relevant resources.

Adding a description to the experiment run
We can also from here add a description for the model. Let's add one now. As a note, the dark mode in this version causes issues with the rich text editor so the below screenshot is in light mode.

Now when we save this description we can see that the model overview page has been updated with the description and tag:

Exploring the model metrics
Navigate now to the model metrics page, and we can see the measurements we logged earlier during our k-fold cross validation:

Exploring the model artifacts
Finally, navigate to the Artifacts page. This is where our model files can be viewed. MLFlow also has strong sklearn integration, so we can see some extra information on how to utilize our model:

Utilizing the model to make predictions
We can use the instructions here to infer the model. In the section, copy the text for the logged_model. In our example it is:
logged_model = 'runs:/0b767b36c4b141b0ade7a5d3d2335f56/logistic_regression'
Open the infer_iris.py in an editor of your choice and replace the line for the logged_model with the values you copied from the models artifacts page.
Infer the model by running the following command:
python infer_iris.py
It will demonstrate the models performance, however it comes with a big caveat - we are testing this model on the same data we used for training it. This is a terrible practice that should be avoided but for now we just are illustrating how to utilize the model artifacts via mlflow.
Expected Output:
>> Predictions: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
>> Actual labels: [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
>> Prediction was correct: [ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True]
>> Accuracy: 1.00 (30/30)
Performing a second run in the experiment
We can have multiple runs in an experiment. Each time it will create a run and log it per our script in MLFlow. Let's run our experiment again without changing any of the code.
python train_iris_01.py
Note: While this will create a new run complete with its own metadata and model artifacts, it will be identical to the first run, since we are using a seed for the cross-validation.

We can access this model run as before and add tags and a description via the UI.
Alternatively, we can programmatically set the tags and description of our model run.
Programmatically setting tag values
We can set tags with the mlfow.set_tag method. Using the mlflow.note.content key in the method, we can set the description.
In train_iris_02.py we have added the following below the with statement:
# Set description
mlflow.set_tag("mlflow.note.content", "A basic logistic regression model using the iris dataset.")
# Set other custom tags
mlflow.set_tag("model_type", "logistic_regression")
Try this out by running:
python train_iris_02.py
Go to localhost on port 8080 and go to the run we just created. Notice how the description and tag are already set, so we don't have to do it via the UI.
We can leverage this functionality to set our descriptions and tags with contextual information on the run.
Read More: MLOps Maturity Model
Nested Runs
Setting up a nested run
We may want to split our experiments in to different stages (such as data preparation, training, evaluation etc.).
For this, we can leverage nested runs. We do this by nesting calls to mlflow.start_run method inside the parent run method and setting nested=True.
Inside train_iris_03.py we add child runs like for example for training the model as below:
with mlflow.start_run(run_name='Model Training', nested=True):
# Train model on the training dataset
model.fit(X_train, y_train)
# Log model
mlflow.sklearn.log_model(model, "logistic_regression")
The script separates our model run in to four stages, that may be typical of your ML workflow:
Data Preparation
Cross-Validation
Model Training
Model Evaluation
Let's run this script to generate a new run in our experiment:
python train_iris_03.py
Exploring the nested experiment run in the UI
We can see under the experiment tab, that our experiment has the various stages separated our as child runs within the parent run.

We can explore each of these stages separately now. Each child run contains its own set of legged metrics, parameters, tags, description and artifacts.
Our model artifact can be found under the Model Training run.

We can view our models test performance at the model evaluation run. Note that in this iteration, we have performed some data pre-processing where we split our training and test data from the beginning.
This means that we now more closely align to best practices - however for this sample model, it hardly matters. Apologies to the botanists out there but this model has incredibly low stakes.
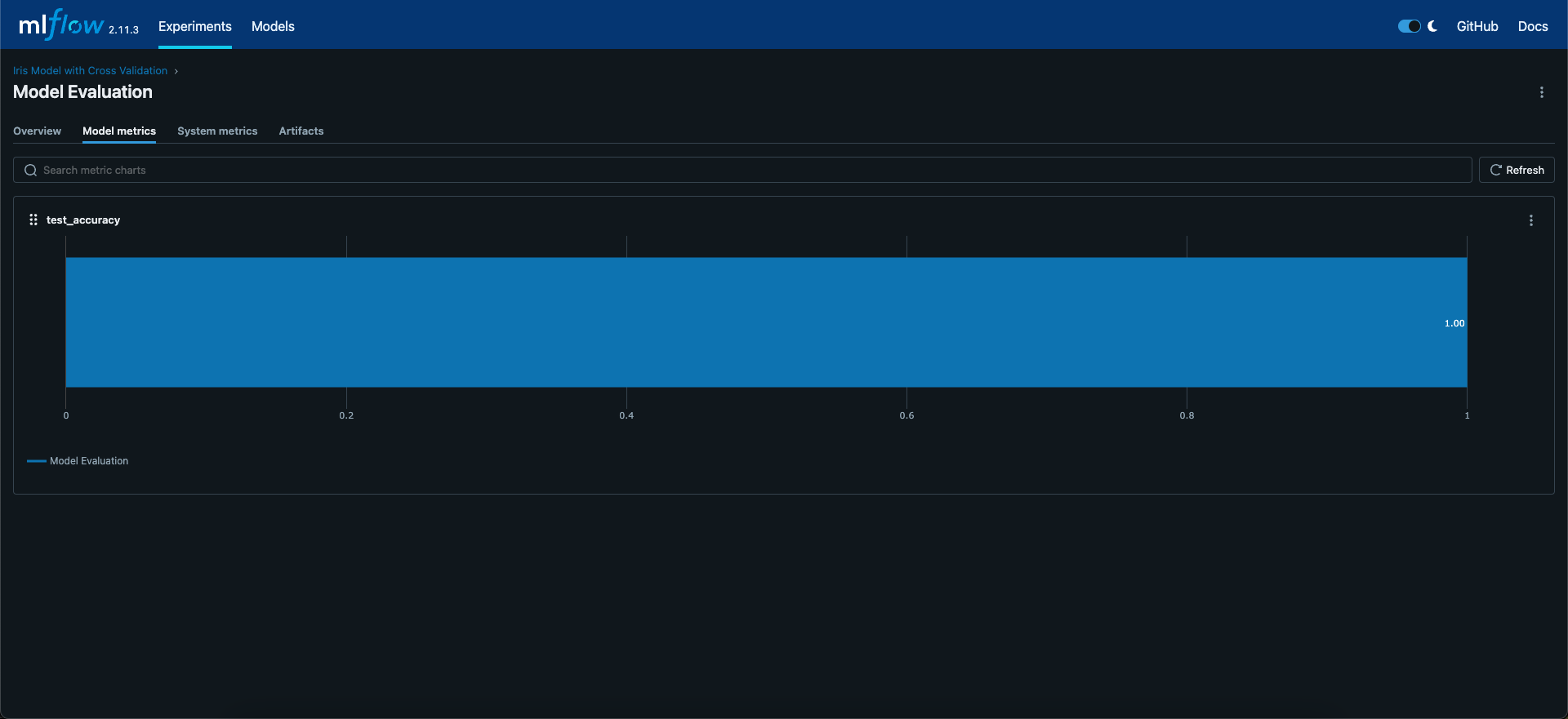
Note that if we want to log tags or descriptions for each of the child nodes, we have to do this separately. We have not done so here, but the parent node does contain the same tags and description as the previous experiment runs.
Adding Additional Artifacts
We have logged the model as an artifact earlier - but we are not limited to just models. We can log other artifacts to our different runs, like plots, files, etc. Use mlflow.log_artifact to log an individual file or mlflow.log_artifacts to log multiple files in a directory as artifacts.
In our final experiment run, we will log the source code as an artifact using the os module by adding the following to the end of our parent run:
# Log the source file as an artifact
with open(os.path.basename(__file__), "r") as f:
mlflow.log_artifact(f.name)
Let's execute this run, then navigate to the run at localhost on port 8080:
python train_iris_04.py
The source file will appear under the artifacts of the parent run as below:
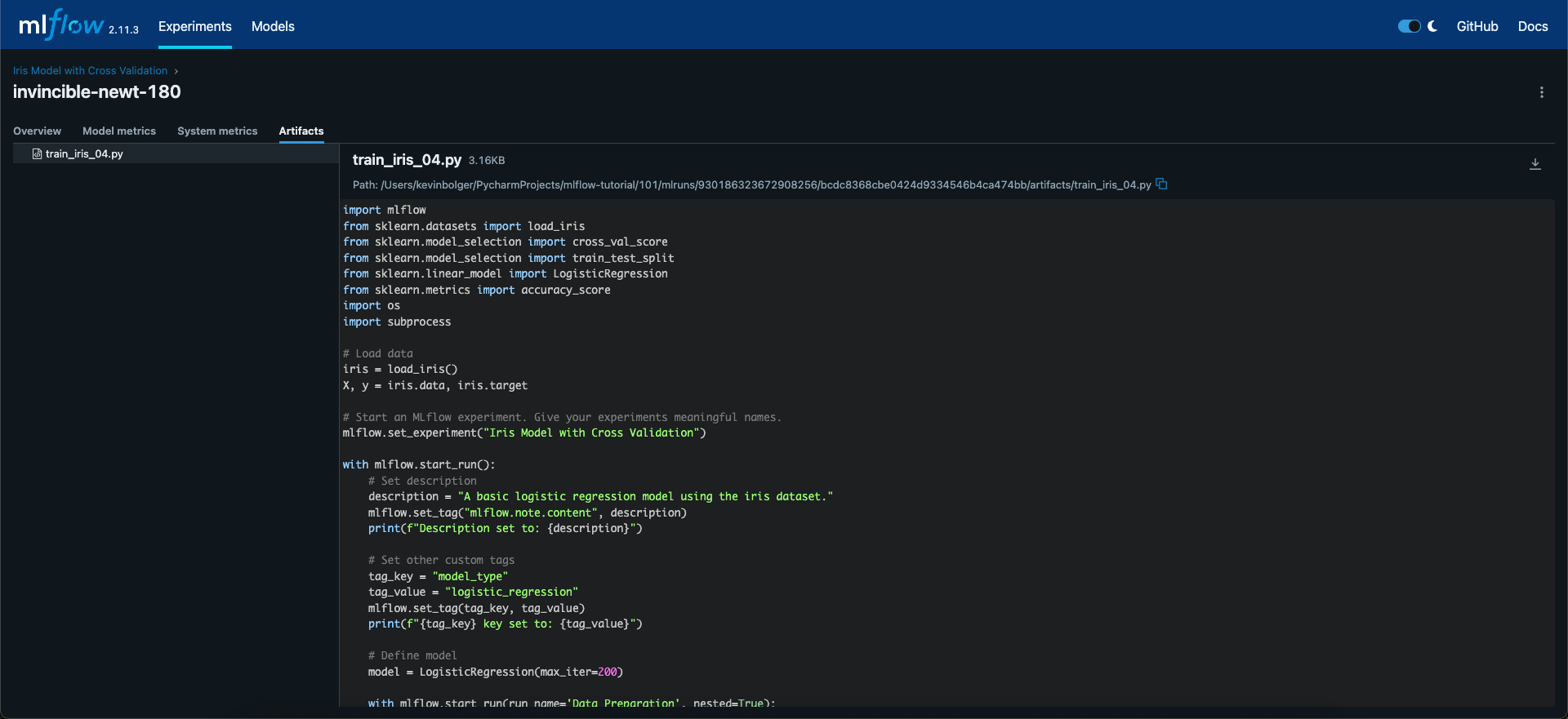
Logging source code in this manner is not required, especially if you are running your experiments from a git repo where the commit has is logged - however you can log a variety of things here like datasets, plots etc. for review.
Next Steps
Cleaning Up
If your terminal is still actively connected to the docker container, type exit to exit the container.
In your terminal, ensure you are currently located in the root directory of the mlflow-tutorial repository. If you ran this tutorial outside of docker, you should be located in the Chapter01/python folder.
We will start by stopping the container and removing it from docker:
docker stop mlflow_chapter_01
docker rm mlflow_chapter_01
We should also remove the mlruns and .venv directories generated by the docker container. Either delete these manually or via the command line, if you have bash with:
rm -rf Chapter01/python/.venv
rm -rf Chapter01/python/mlruns
Next Steps
Congrats! If you have made it to the end, you have crawled your way to the finish line and set up your first experiments in an MLFlow environment running locally on your machine (either through docker, or natively in your OS).
If you are interested in learning more advanced features of MLFlow, like using the model registry, integrating with tensorflow, hosting the service remotely, deploying models remotely, storing models and artifacts remotely and much more then sign up below for updates and we’ll email you when we release a new MLFlow related walkthrough.